Performance Prediction of Multi-threaded Applications
Co-authored by Nikhil Vinay Sharma & Vishv Shrava Sharma
With multi-core processors becoming the norm, application performance prediction has become an important topic in parallel programming research. Though estimation of application performances becomes really difficult for varying levels of parallelism on different architectures. In this paper, we propose an efficient learning based approach to estimate application performance with varying degrees of parallelism for a specific hardware. We evaluate various machine learning models with respect to how accurately they estimate the speed-up gains for varying levels of multi-threading relative to single and double threaded execution. We evaluate our predictions on publicly available benchmark suit PARSEC 3.0 for applications parallelised in C. Random Forest with Double threaded execution statistics performs the best, achieving correlation coefficients of estimated speed-ups vs actual speed-ups ranging from 0.7 to 0.8 for different number of threads.
Table of Contents
Introduction
Since the past two decades, multi-core processors have become omnipresent in all kinds of computer systems ranging from personal computers to supercomputers. Although parallel programming on multi-core processors sounds promising, in order to exploit the maximum computation out of multi- core processors in a given amount of time, it is imperative to identify the optimal level of parallelism that should be employed for a given task, performing the best for the available multi-core architecture. Hence, it is a major advantage if one can predict the performance of an application based on the level of parallelism introduced in the application. But, due to the increasing complexity of the system architecture, modelling and predicting the performance of programs is a challenging task [1].
Our main contributions are the following:
- We propose a framework to predict program performance for parallel applications parallelised in C using low level feature set obtained from single & double threaded execution and evaluate our approach for multi-threaded applications in PARSEC-3.0 benchmark.
- We compare multiple machine learning algorithms on multiple error metrics and find the best performing model for performance prediction.
- We analyse low-level features and find the features that have a more active role in predicting speed-ups.
Literature Survey
Several researchers have worked and found success in the domain of performance prediction of multithreaded applications. The key focus in most of the research is on finding the hardware and software features of the program which are highly relevant to performance prediction. One of the most common form of performance prediction is to predict the performance of an application on different architectures and their configurations. In 2018, Tarvo et. al. [2] used the information about the structure of the program, the semantics of interaction between the program’s threads, and resource demands of individual program’s components to predict its performance on different architectures.
Another common form is to predict the performance using the hardware independent feature of the software on a given architecture. De Pestel et. al. [3] proposed Rapid Performance Prediction of Multithreaded Applications on Multicore Hardware which breaks up multithreaded program execution into epochs based on synchronization primitives, and then predicts per-epoch active execution times for each thread and synchronization overhead to arrive at a prediction for overall application performance. Hoste et. al. [4] attempt to predict performance on a given hardware solely on the basis of hardware independent program features along with the processor architecture without ever executing the applications. Micro-architecture program features have been extracted from instrumentation tools such as ATOM in [5] and Valgrind in [6].
Agarwal et. al. [7] propose an efficient learning based approach to estimate application performance with varying degrees of parallelism for a specific hardware. They used execution statistics obtained by running the program on one thread, and predicted the speedup for the cases of multiple threads. Our research is an extension on this work as we aim to better the results obtained in their work. We propose the idea that using the execution statistics while running the program on 2 threads is a better approach for multiple reasons. First, when program is running on 1 thread, several bottleneck events like the ones which involves resource contention and context switches are not occurring in case of 1 thread but will be there in the case of running program on 2 threads. Secondly, it may also speedup the process of data collection as running the program on 2 threads will usually take lesser time to finish. To prove our theory, we will be performing different experiments where we build features using execution statistics with 1 thread, execution statistics with 2 thread and execution statistics with both 1 thread and 2 threads. Finally we will compare which case is better to predict the execution performance. In addition to this, we will also focus on shortlisting the features which are more relevant to performance prediction in this scenario.
Core Idea
Agarwal et. al. [7] propose a model that takes a set of program features (extracted from profiling tools along with single-threaded execution statistics) as input and outputs the estimated speedup for an application of interest on the required number of threads. In our approach, we argue that in single- threaded execution statistics, a lot of information is unavailable to the model that is required for making decisions for multi- threaded execution statistics. Since, there is only one thread that is running the program, almost all of the interactions with the memory, caches and other resources are uncontested. There is almost no overhead due to resource contention and con- text switching. When we combine the data for two-threaded execution statistics for multiple data sizes and benchmark applications, we will get a lot of intrinsic trends in the data due to these thread interactions with the resources that can prove more useful in predicting speedups for multiple threads. Thus, any machine learning model will make better decisions with these data patterns. Another advantage of using two threads instead of one for training data creation is that the run-time of applications will be faster and will allow us to create training data faster results as well.
In our approach, we try three different experiments — with only single threaded execution statistics, with only two- threaded execution statistics, with combined single and two- threaded execution statistics to create the training data. We then compare if the results follow our hypothesis.
The models are trained in a supervised fashion on 21 workloads obtained from PARSEC 3.0 using actual speedups obtained from execution on the hardware for the required number of threads. Each of the 21 workloads has been executed for 4 different problem sizes providing us 84 applications in total.
We now go through the two components of this framework, namely Feature Extraction and Machine Learning Modelling to predict speed-up for various numbers of threads.
Feature Extraction using Data Scraping
Using profiling tools such as Perf along with one and two-threaded execution statistics, we extracted the following features from each of the applications:
- Hardware Events include features like branch- instructions, branch-misses, cache-misses, cache- references, cpu-cycles and instructions
- Software Events include features like alignment faults, context-switches, cpu-clock, emulation-faults and major- faults.
- Hardware Cache Events cache misses, loads and prefetches for various level of caches. Cache Misses reduce the performance of parallel programs by introducing overheads due to cache coherence.
Machine Learning Modelling
Given the feature set obtained from instrumentation and one & two-threaded execution along with speedups for var- ious multi-threaded implementations for applications in the benchmark suite, our objective is to create and fine-tune a function between them, such that for features obtained from any new application, that function can predict the speedups for various levels of multi-threaded executions. We use python based skicit-learn library for modelling. We use regression based models such as Linear Regression, Gaussian Process Regression, K Nearest Neighbors Regression and Random forest Regression. We also use try hyper-parameter tuning and regularization for to prevent over-fitting on the dataset.
Experimental Setup
Benchmarks
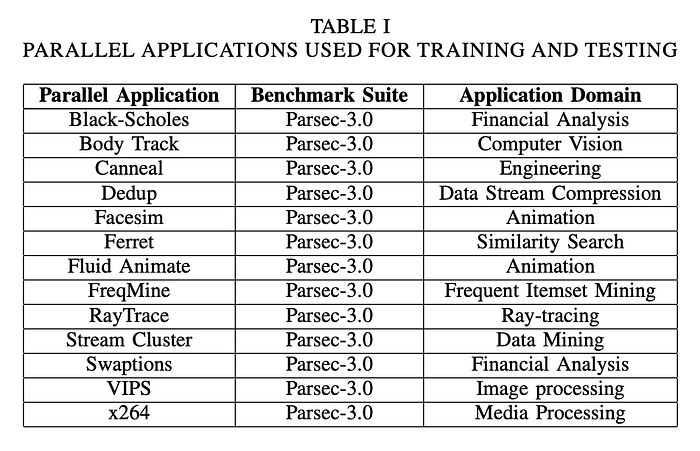
We evaluate our approach on a well-known benchmark suit — PARSEC 3.0 [9]. Both the benchmarks suites comprise of multi-threaded workloads for a wide variety of complex applications like computer graphics, financial modelling, and numerical analysis. Applications in the PARSEC-3.0 comprises of applications parallelized using OpenMP and p-threads in C. We finalized a total of 13 application workloads from PARSEC benchmark suit. Table I contains all the 13 workloads selected by us where each workload was executed with four different input sizes.
Tools and Machine Specifications
We generate execution statistics of applications with perf [9], a performance analysis tools for Linux while executing them on a real linux machine rather than using cycle accurate simulation. We used python for scraping the log files and for machine learning modelling skicit-learn library [x] has been used. For running our benchmark applications we used the CIMS Compute Servers — mainly ’crunchy’ (Four AMD Opteron 6272, 2.1 GHz, 64 cores, Memory 256 GB) servers were used.
Data-set preparation
Machine learning models run on the ‘garbage in, garbage out’ principle, hence it becomes imperative that the data used to train these models is assimilated correctly. Most of our efforts were spent on building a reliable feature set capable of estimating the desired performance metrics. Each work- load was executed with 4 different input sizes — ‘simsmall’, ‘simmedium’, ‘simlarge’, ‘native’; on 1, 2, 4, 8 16, 32, 64 threads separately with perf on different linux machines. We created scripts to run these jobs and store log files with useful information.
We used python to scrape these log files and collect the data in a pandas data frame. We also plotted the speedups for each data size, for each application to detect outliers and removed them. We further remove the benchmark application names in our data, so that we are only passing the features extracted from perf about the various statistics of the programs.
The features that we use to estimate speedups, such as instruction count and L1 cache miss rate vary greatly in magnitudes. Since we’re trying to predict speedups, we use regression modelling techniques in order to estimate the relationship between speedup and features we’re trying to solve Since, unbounded numerical features skew the error metric in the direction of a particular feature, it is important that we normalize the numerical features. We normalized all the numerical features such that they have a mean of 0 and variance of 1. We also one-hot encode all the categorical features.
We created separate data sets for each experiment — dataset with only PARSEC applications in order to do a comprehensive analysis on what features are useful in improving predictive performance.
Training and Evaluation
After pre-processing, we split the data around 80–20%, into training and test data sets. The split is done based on applications runs information, i.e., the model is never trained on some application benchmarks, reserved in test data, and must try to learn this information from the training data.
We split the data 3 different ways, and create data for three different experimental conditions:
• Training only on application run statistics extracted out of single-threaded runs: We train our model on this data of single-threaded runs and estimate speedups for different applications for different thread sizes, that the model has never seen before.
• Training only on application run statistics extracted out of two-threaded runs: We train our model on this data of two-threaded runs and estimate speedups for different applications for different thread sizes, that the model has never seen before.
• Training on combined application run statistics extracted out of single-threaded runs as well as two-threaded runs: We train our model on this data of single-threaded runs and estimate speedups for different applications for different thread sizes, that the model has never seen before.
Since the amount of data is relatively small (in comparison to a typical machine learning problem), we need to ensure that our models do not over-fit on the data. We experi- ment with different regularization techniques like L1 and L2 regularization in order to overcome this. We evaluate all these algorithms on multiple metrics like — Mean absolute Error, Mean Squared Error, R2 score as well as matching estimated correlation coefficients and observe that Random Forests Regression performs the best for all evaluation metrics.
We can use the trained model to predict the speedups of an unobserved application, using features obtained from the execution of PARSEC applications, on different number of threads and just use the number of threads needed for maximum speedup.
Lastly, we use cross-validation on the data set in order to evaluate the models.
Experiments & Analysis
In order to know which features are more important and useful in predicting speedups, we use the Random Forest Regressor to rank feature importance. Random Forest uses multiple Decision Trees which are trained on parts of data chose randomly. These decision trees find conditions to split the tree based on using Gini-index information gain. Using these information gain (or entropy), the Random Forest is able to determine the most important features in predicting speedups. The below figure 1 gives us the feature importance.
We can see that the features — number of Threads, minor- faults, page-faults, llc-load-misses, have the most impact on the model.

In order to evaluate the model for the three experiments, we use mean absolute error and correlation coefficients between the predicted & actual speedups. These can be seen in the below tables.
We can see that Model Evaluation with Double-Thread Execution produces the best results on average, this may be because double-threaded execution gives the model most relevant data in order to make a decision. Surprisingly, double threaded execution also performed better than combined single and double threaded execution. This might be because adding information pertaining to both runs increase the features for our model two-fold and may be resulting in over-fitting to some extent. Also, single threaded execution data might not be more relevant towards predicting performance of multiple threads.
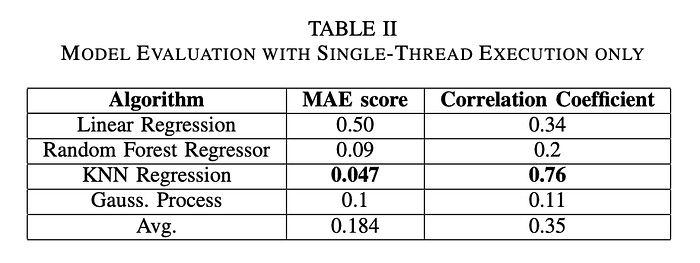
We can see that the non-linear models such as Random Forest & K Nearest Neighbors model produce the best results. Random forest are generally better at prediction as compared to linear based models as they can form non-linear decision boundaries for prediction. Pruning on the data and using more than 50 trees ensures that we do not over-fit on the data set as well. However, since the data is small, non-learning based algorithm KNN was found to be more robust with different variety of inputs.

Conclusions
Our main conclusions are:
• Double threaded Execution statistics give the model more relevant data to make the decisions, as the execution statistics contain information about resource contention amongst the threads.
• Double threaded execution also performed better than combined single and double threaded execution on average. This might be because of over-fitting due to more features or single threaded execution data might not be more relevant towards predicting performance of multiple threads
• In order to predict parallel performance for applications, minor-faults, page-faults and llc-load-misses as input features proves to be most impactful.
References
[1] X.Zheng, P.Ravikumar, L.K.John, and A.Gerstlauer,“Learning-based an- alytical cross-platform performance prediction,” in 2015 International Conference on Embedded Computer Systems: Architectures, Modeling, and Simulation (SAMOS), pp. 52–59, IEEE, 2015.
[2] Tarvo, Alexander Reiss, Steven. (2018). Automatic performance pre- diction of multithreaded programs: a simulation approach. Automated Software Engineering. 25. 1–55. 10.1007/s10515–017–0214–5.
[3] Sander De Pestel , Sam Van den Steen , Shoaib Akram, and Lieven Eeck- hout. RPPM: Rapid Performance Prediction of Multithreaded Applica- tions on Multicore Hardware. IEEE COMPUTER ARCHITECTURE LETTERS. VOL. 17, NO. 2, 2018.
[4] K. Hoste and L. Eeckhout, “Microarchitecture-independent workload characterization,” IEEE micro, vol. 27, no. 3, pp. 63–72, 2007.
[5] K. Hoste and L. Eeckhout, “Comparing benchmarks using key microarchitecture-independent characteristics,” in 2006 IEEE Interna- tional Symposium on Workload Characterization, pp. 83–92, IEEE, 2006.
[6] T. Hoshi, K. Ootsu, T. Ohkawa, and T. Yokota, “Runtime overhead reduction in automated parallel processing system using valgrind,” in 2013 First International Symposium on Computing and Networking, pp. 572–576, IEEE, 2013.
[7] Agarwal, Nitish, Tulsi Jain, and Mohamed Zahran. ”Performance pre- diction for multi-threaded applications.” International Workshop on AI- assisted Design for Architecture. 2019.
[8] C.Bienia, S.Kumar, J.P.Singh, and K.Li,“The Parsec Benchmark Suite: Characterization and architectural implications,” in Proceedings of the 17th international conference on Parallel architectures and compilation techniques, pp. 72–81, ACM, 2008.
[9] A. C. De Melo, “The new linuxperftools,” in Slides from Linux Kongress, vol. 18, 2010.
